
ONIONでデータを保存・管理する
研究データの取得・収集・保存・解析 〈実践編〉
2025年10月1日から2026年9月30日まで、無料でONIONをご利用いただけます。以下の1.1に無料利用の申請方法を記載しています。
本ページでは、研究データをONIONで保存・管理するにあたり、共同研究プロジェクトを想定して、解説いたします。研究チームでデータを共有しながら、研究を進めていく過程を説明いたします。
研究プロジェクトの事例
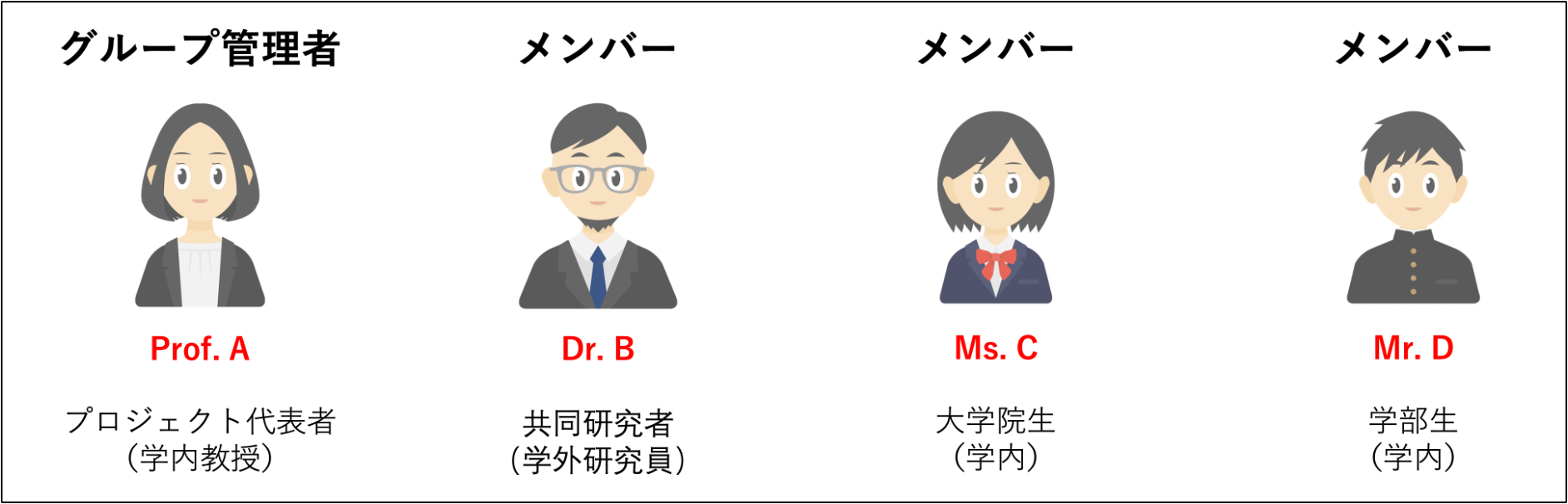
本事例は、大阪大学の研究者(Prof. A)、学外の共同研究者(Dr. B)、大阪大学の大学院生(Ms. C)、および学部生(Mr. D)で構成される共同研究プロジェクトにおいて、研究データエコシステム「ONION-Object」を活用し、データを共有・管理するための具体的な手順を示したものです。なお、プロジェクト代表者には大阪大学の研究者であれば、だれでもなることができます。
1. 申請準備
1.1 グループ管理者(Prof. A)のアカウント申請
ONION-Object のアカウント申請手順を、以下の図に示します。
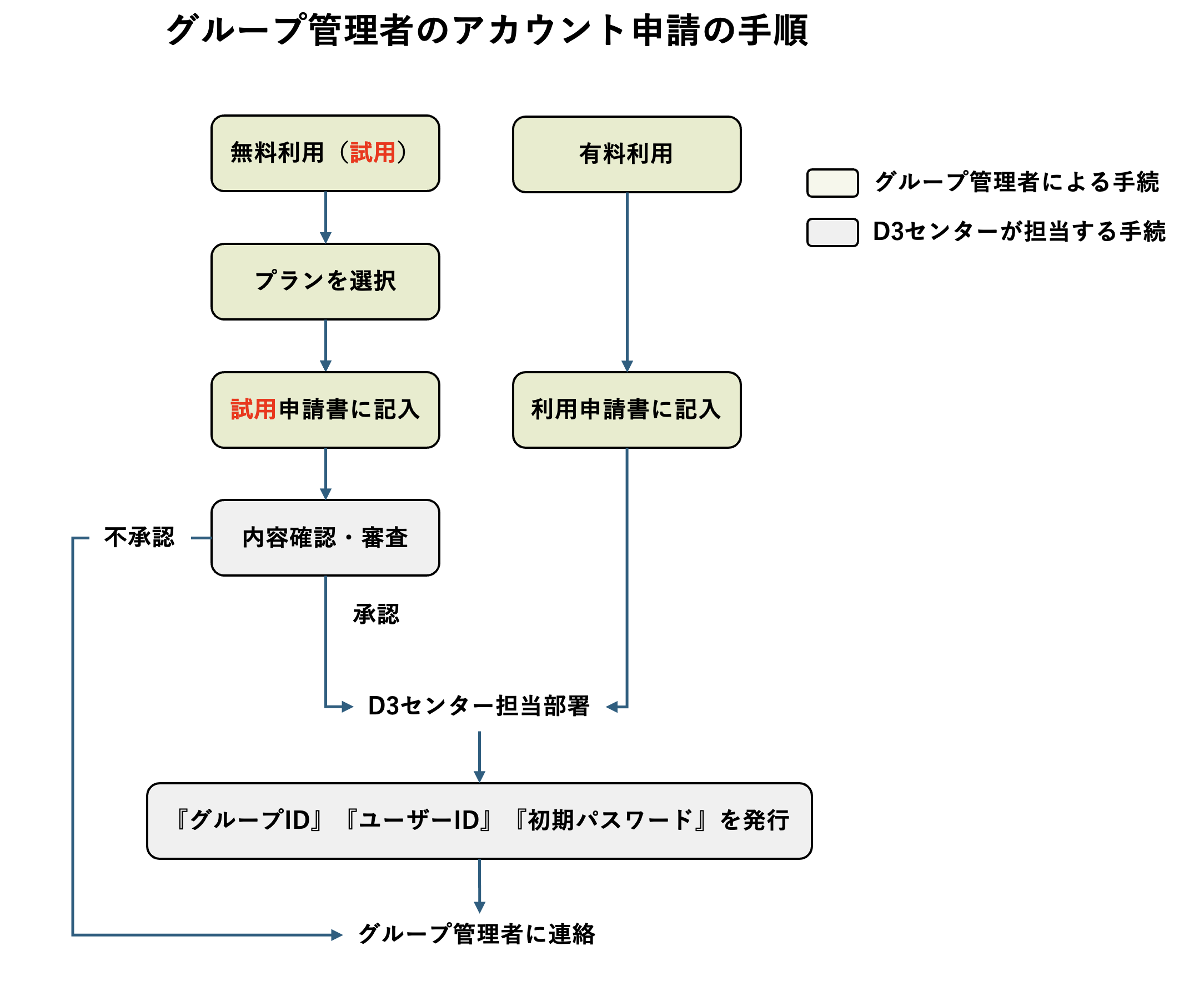
1.1.1 無料利用(試用)
初めてご利用いただくユーザー様には、試用期間として無料でご利用いただけます。つきましては、下記の試用申請書をダウンロードのうえ、ご記入ください。
ご利用手順は以下の通りです。
(1)ご利用プランを選択してください。
(2)選択したプランを、試用申請書にご記入のうえ、onion-trial@ml.office.osaka-u.ac.jp宛にご提出ください。
(3)内容確認・審査後、承認された申請書はonion-trial@ml.office.osaka-u.ac.jpより D3センター 大規模計算機システム担当へ送付されます。
2025年10月より1年間、研究データ用領域を無料で利用していただけますが、アカウントは申請のあったグループ管理者のみ登録いたします。グループ内の利用者へのアカウント登録手続きは、以下の1.4に示す手順でグループ管理者が行なってください。
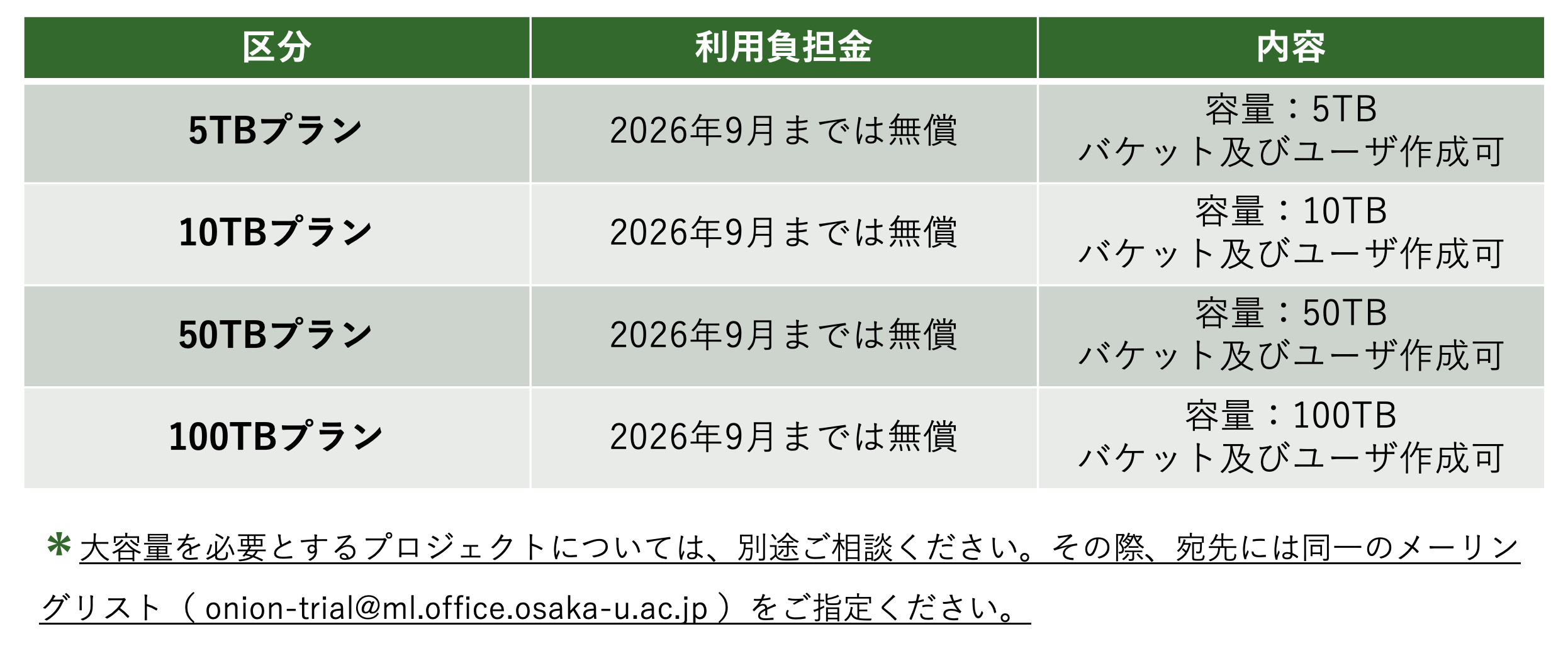
1.1.2 有料利用
グループ管理者(Prof. A)は、利用申請書①にご記入のうえ、②の system@cmc.osaka-u.ac.jp へご提出くださいますようお願いいたします。

2026年9月以降はONIONの利用料をお支払いいただくこととなります。
複数のプロジェクトでご利用の場合は、利用割合を定めていただくことで、利用料の分割請求が可能です。
詳細はこちら:申請・利用負担料金について
1.1.3 無料利用の場合も、有料利用の場合も、D3センター担当部署より以下のような『グループID』『ユーザーID』および『初期パスワード』が発行されますので、少々お待ちください。
1.1.4 グループ管理者(Prof. A)は、送付されてきた情報に基づいて、ONION-ObjectのWEB管理画面にログインしてください。
※ 2026年1月11日~14日の ONION-object メンテナンス後、ONION-object へのアクセスURLが変更されています。 (旧)https://onionportal.hpc.cmc.osaka-u.ac.jp:8443 (新)https://onionportal.onion.osaka-u.ac.jp 旧URLではアクセスできませんので、必ず新しいURLをご利用ください。 詳細は このページ をご参照ください。
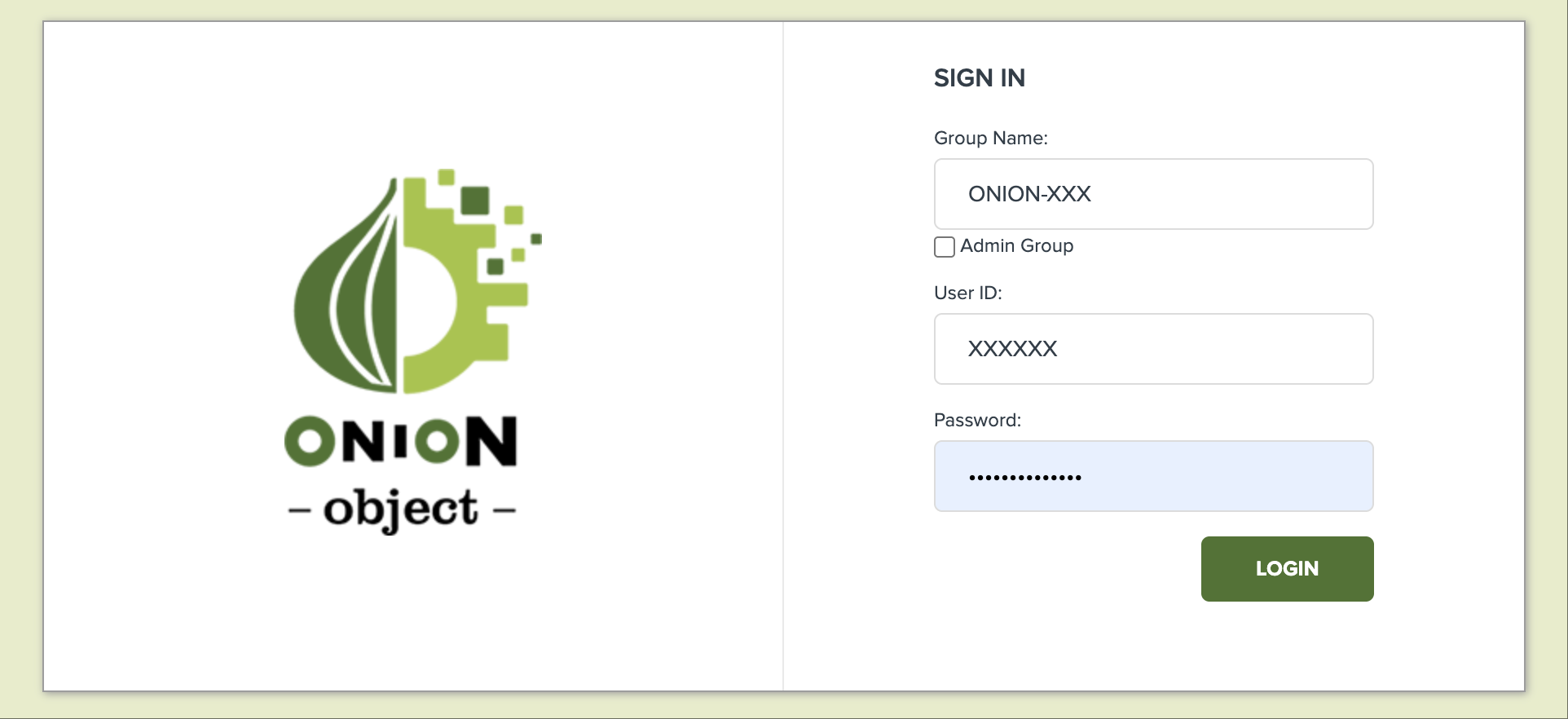
1.2 初回ログインおよびパスワード変更
初回ログイン時には、初期パスワードから新しいパスワードに変更するようにしてください。以降、図中の番号にしたがって、操作をしてください。

なお、セキュリティを高めたい場合は、多要素認証(MFA)も使用していただくことができます。設定手順は以下の通りです。
1.2.1 下図の①「MULTI-FACTOR AUTHENTICATION (MFA)」が「Disabled」(デフォルト)の場合、クリックして「Enabled」に変更します。
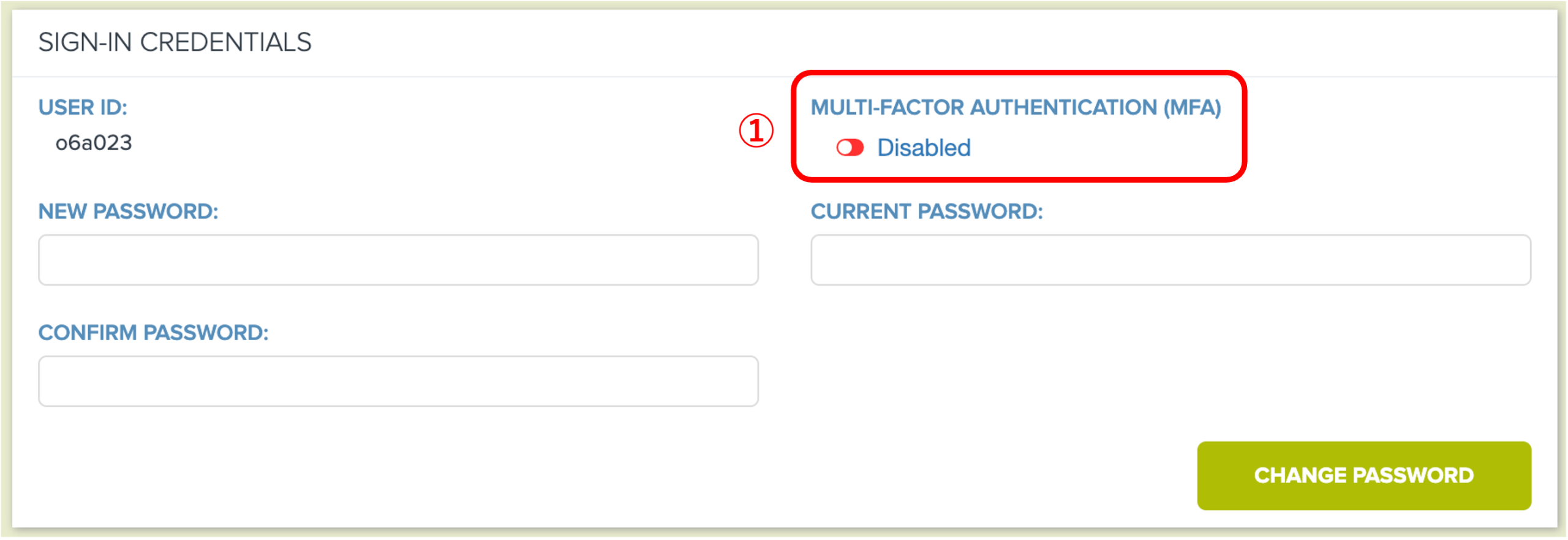
1.2.2 表示される下図のページで、MFAデバイス(スマートフォンなど)の認証アプリ(例:Microsoft Authenticator)を使い、②のQRコードをスキャンするか、またはSECRET KEYを手動で入力します。デバイスの設定が完了したら、認証アプリに表示される連続する2つのMFAコード(通常は30秒ごとに更新される6桁の数字)を、上の図の③に入力し、④「Submit」ボタンをクリックして送信してください。
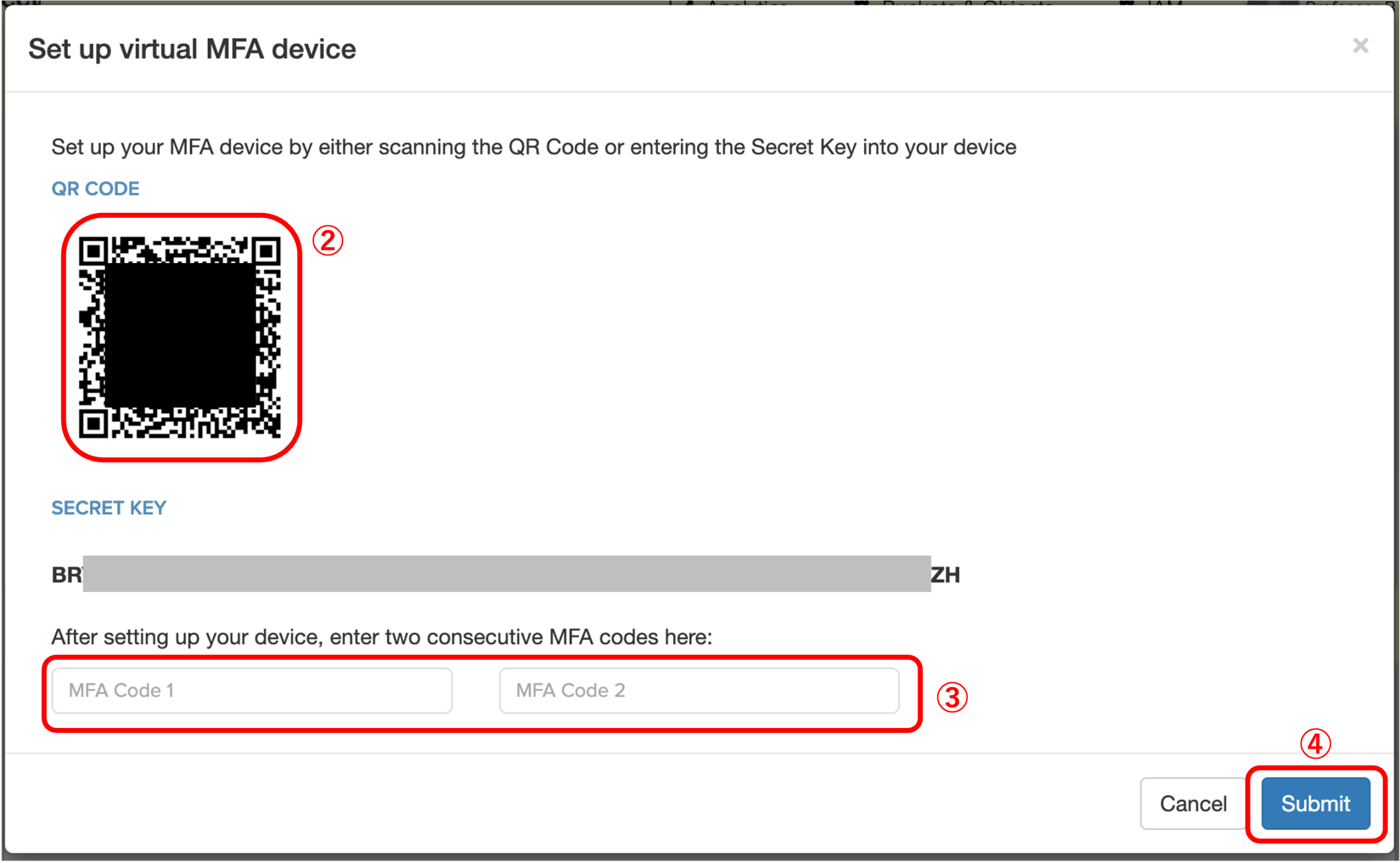
1.2.3 設定が成功すると、下図の画面が表示されます。「Ok」をクリックしてください。
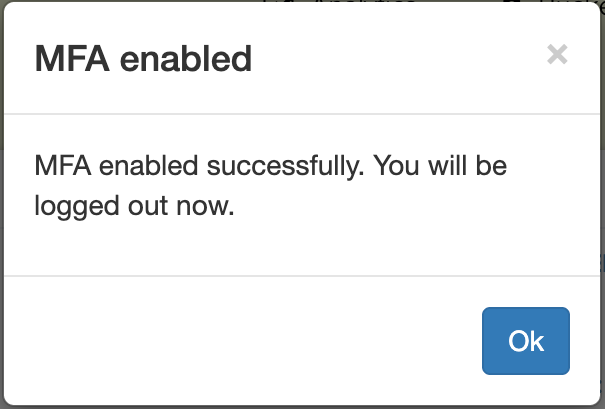
1.2.4 その後、Dr. B がONION-ObjectのWEB管理画面に再ログインすると、6桁のMFAコードの入力が求められます。正しく入力するとログインが完了します。

1.3 グループ管理者(Prof. A)のデータアップロード
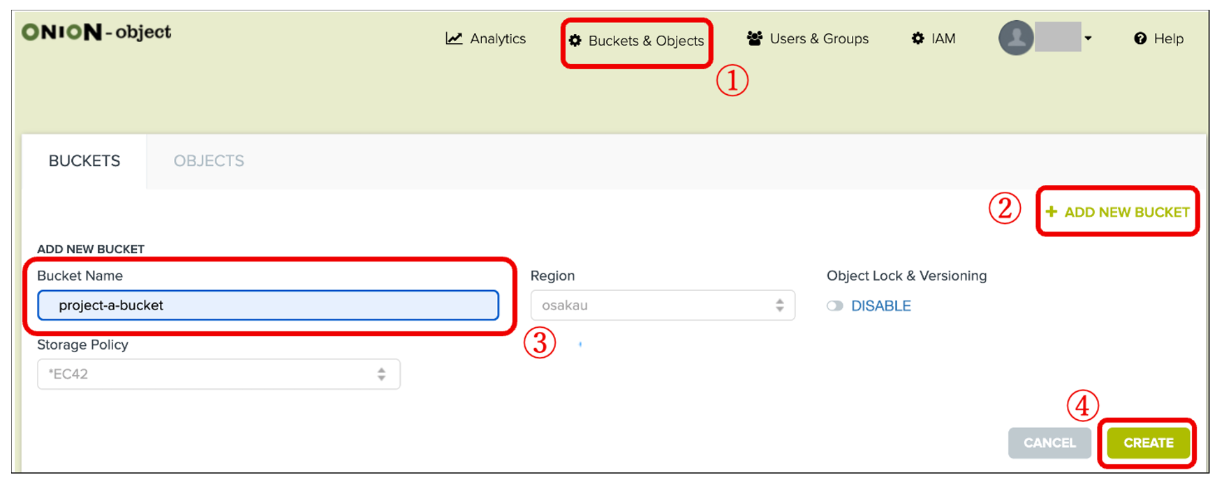
1.3.1 ONION-Objectでは、バケットという入れ物に入れてデータを管理します。バケットの中にフォルダを作って階層的に管理することができます。まず、研究プロジェクトで使用するためのバケット(例:project-a-bucket)を作成します。
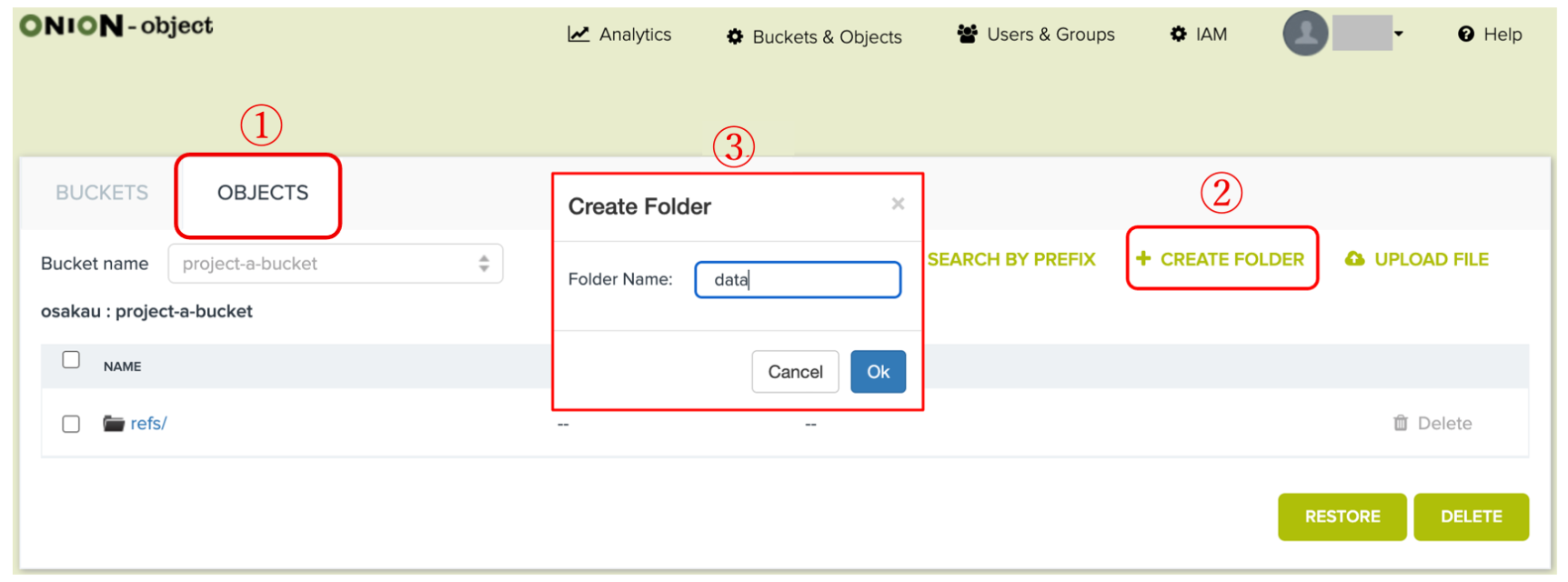
1.3.2 『project-a-bucket』内にdataという名前のフォルダを作成します。
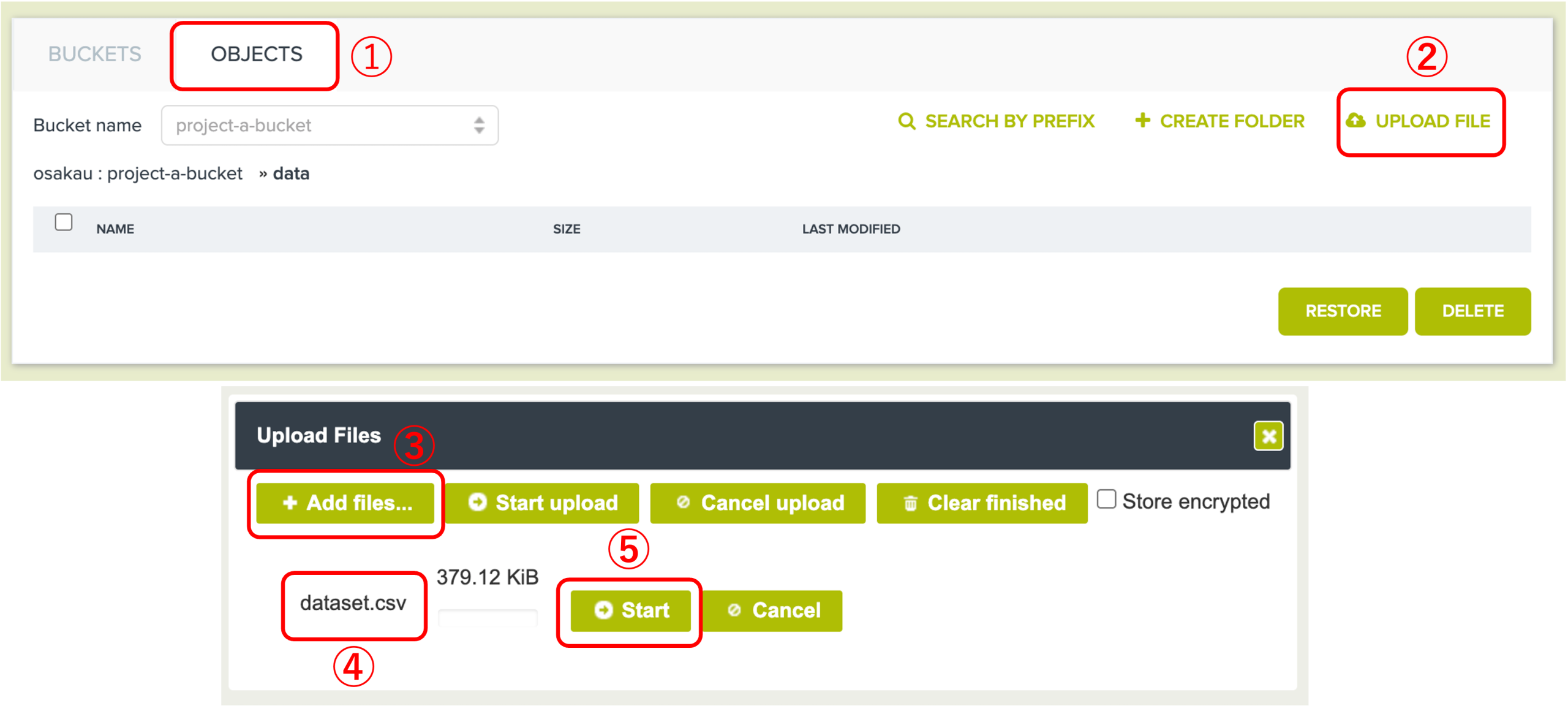
1.3.3 UPLOAD FILE ボタンをクリックし、Add files を選択すると、ファイル選択画面が表示され、アップロードする dataset.csv を指定してStartをクリックします。
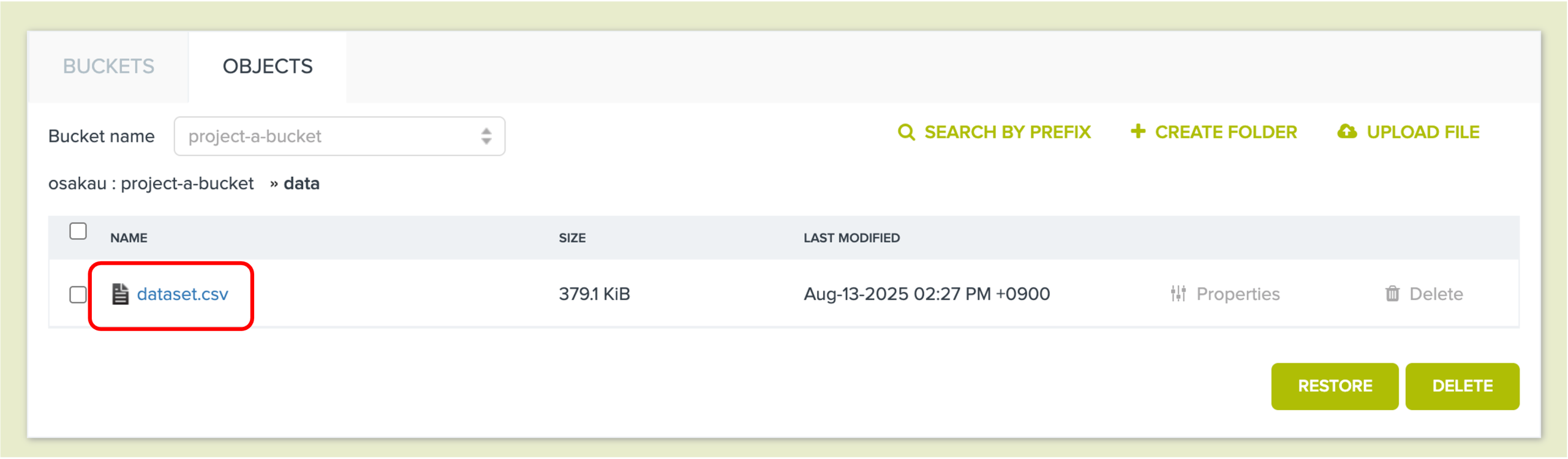
作成したdataset.csvは、dataフォルダ内に保存されています。
1.4 グループ管理者(Prof. A)はメンバー(Dr. B、Ms. C、Mr. D)のアカウント作成
ONION-Objectでは、管理権限をもつ管理者が自由にファイル共有者のユーザIDを作成することができます。ここでは例として、Dr. B のアカウント作成方法を紹介しますが、他のメンバーも同様の手順で作成します。
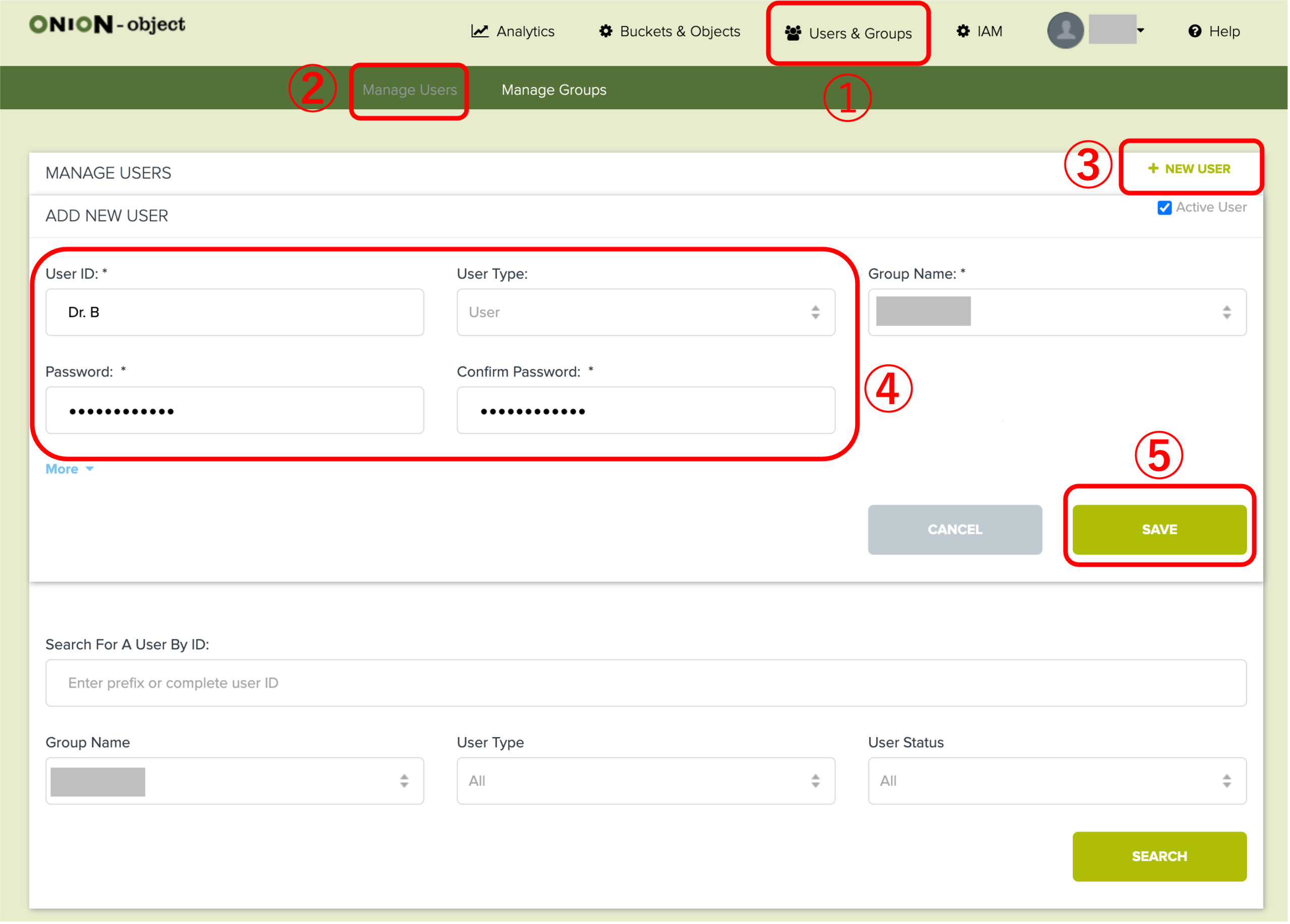
1.5 ユーザーIDおよび初期パスワードの連絡
Prof. A は Dr. B にグループID、ユーザーID、初期パスワードを知らせます。Dr. B は初回ログイン時にパスワードを変更してください。MFA認証を設定する場合は、1.2の手順を参照してください。

メンバー4名のアカウント作成が完了した後、それぞれの関係は下図の通りです。
Prof. A、Dr. B、Ms. C、Mr. D はそれぞれ独立したバケットを持つことができます。
- Prof. A はグループ管理者として、自身の独立したバケットを所有しています。
- Dr. B は学外研究者として、独立したバケットを所有しています。
- Ms. C と Mr. D は大阪大学の学生として、それぞれ独立したバケットを持っています。
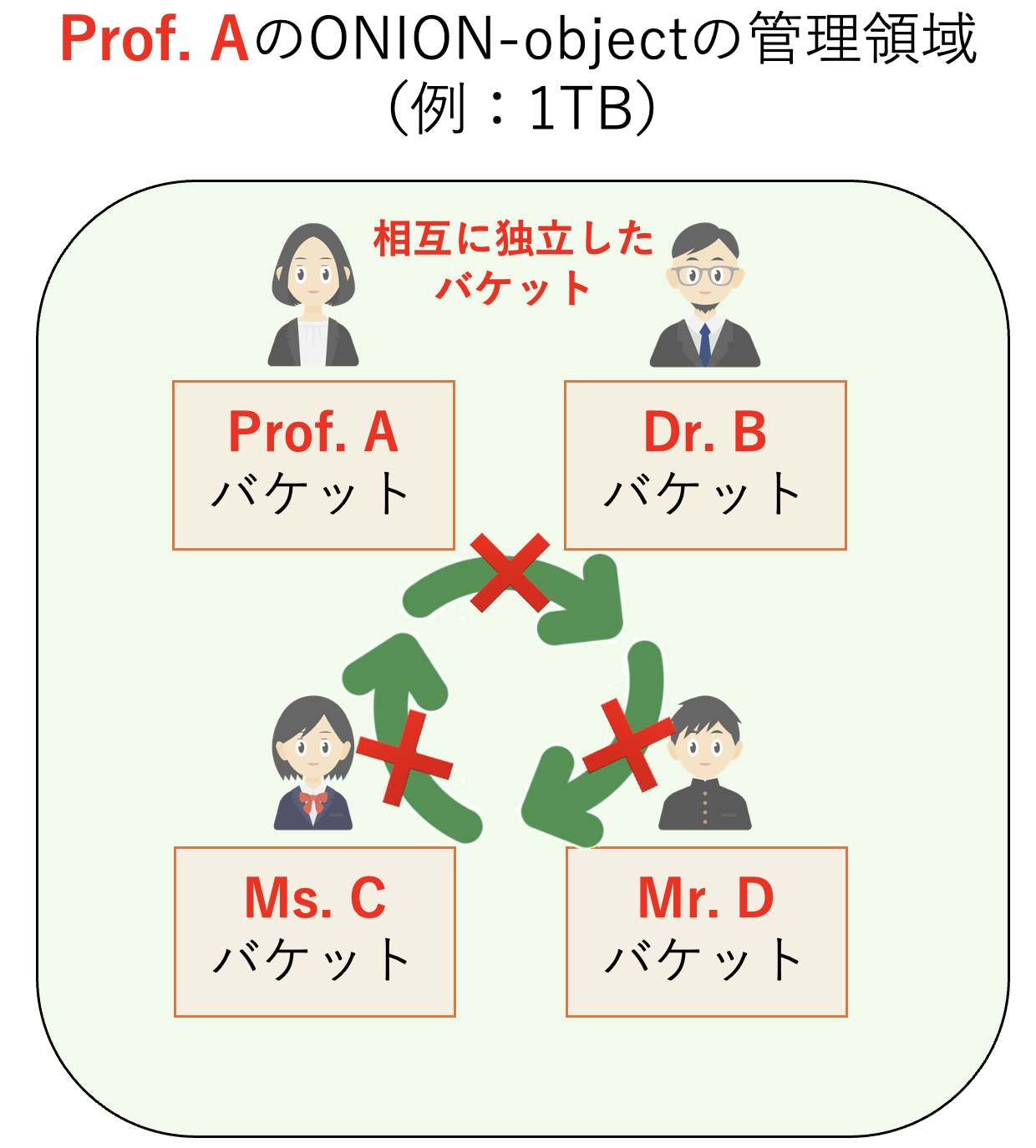
図の青い枠は、これら4つのバケットが同一研究プロジェクト( Prof. A が管理するONION-Object領域)に属していることを示しています。各メンバーのバケットは独立管理されており、データの隔離と安全性が確保されています。プロジェクト全体は Prof. A が管理していますが、データは個別に保持され、各バケットへは、バケットを作成したユーザが許可しない限りアクセスできません。
2. メンバー間のデータ共有(Prof. A から Dr. B への共有を例に)
2.1 データ所有者(Prof. A)による共有権限の設定
バケット単位またはファイル単位でグループ全体または個別のユーザへの共有設定が可能です。バケットへのアクセス許可(閲覧のみ)、ファイルの共有(ダウンロード)の順番に行なっていきます。
例1:project-a-bucketを例に、すべてのメンバー(Dr. B、Ms. C、Mr. D)にアクセス許可(閲覧のみ)を与える場合:
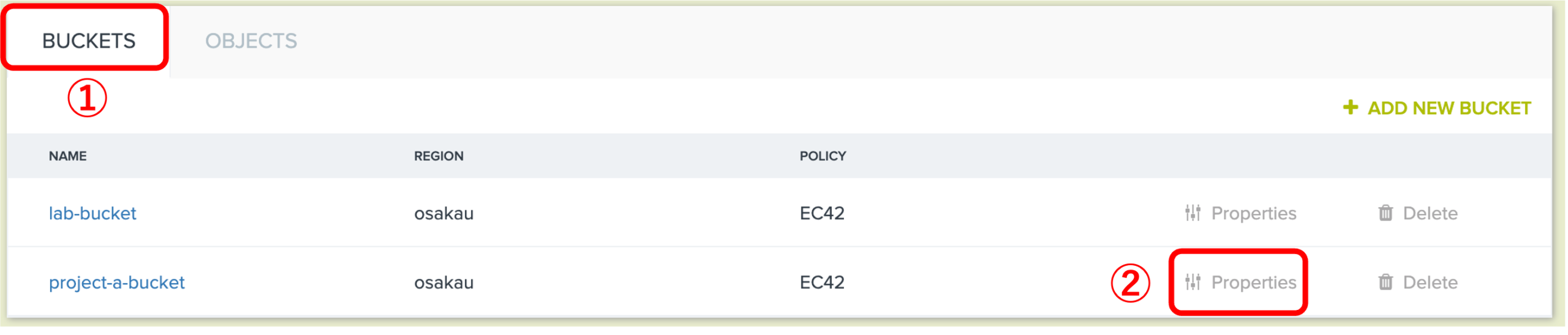
2.1.1 まず、① BUCKETS 画面で共有対象のバケット名を選び、② Properties をクリックしてください。
Prof. A は「Authenticated users」にチェックを入れることで、バケットの共有設定をすべての認証済みユーザー(Dr. B、Ms. C、Mr. D)にもアクセス許可(閲覧のみ)を与えることができます。
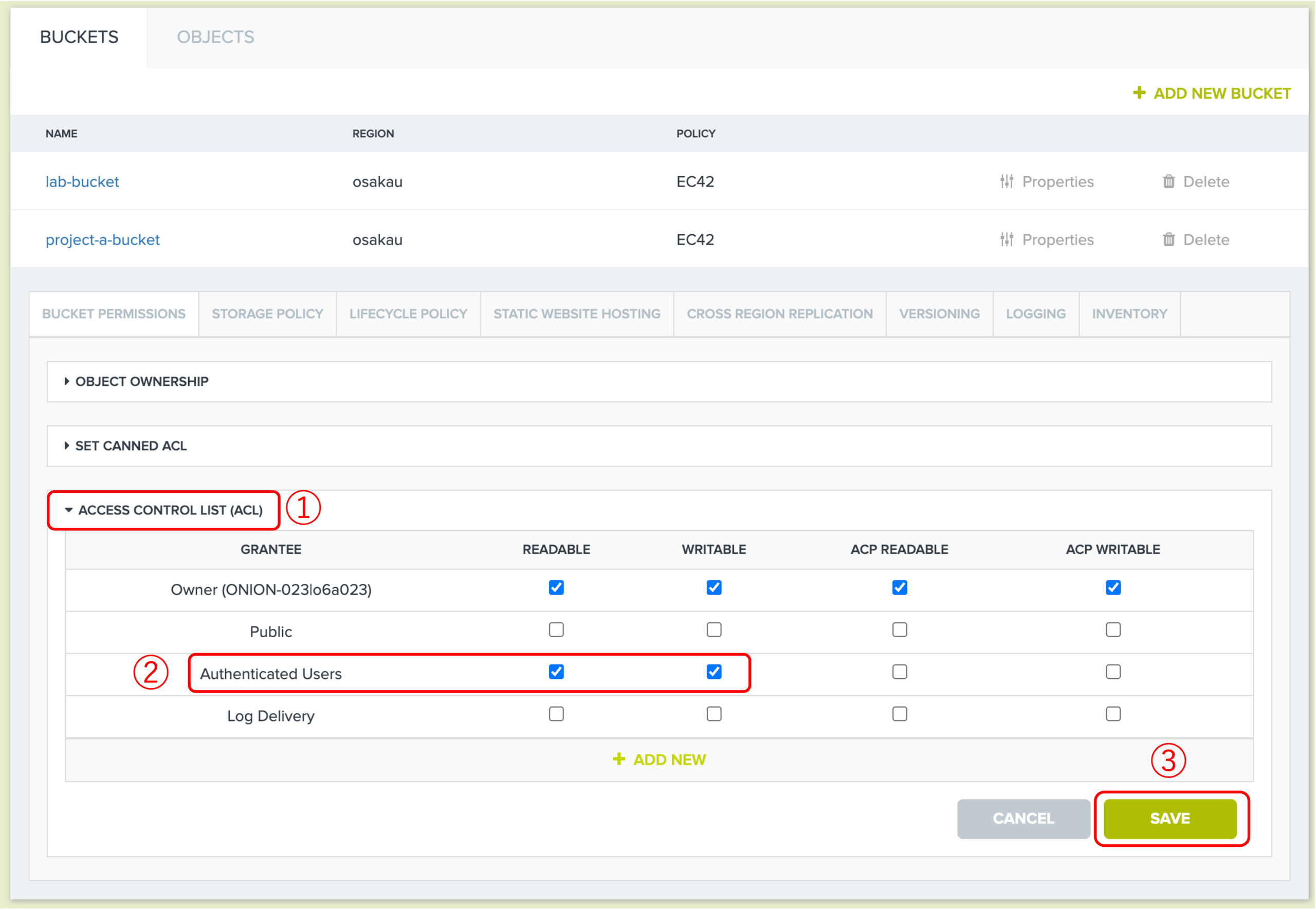
例2:project-a-bucketバケットを例に、Dr. B だけにアクセス許可(閲覧のみ)を与える場合:④にGroup Name|User ID(User IDは1.4節で作成したID。|の前後にスペースは不要)を入力してください。
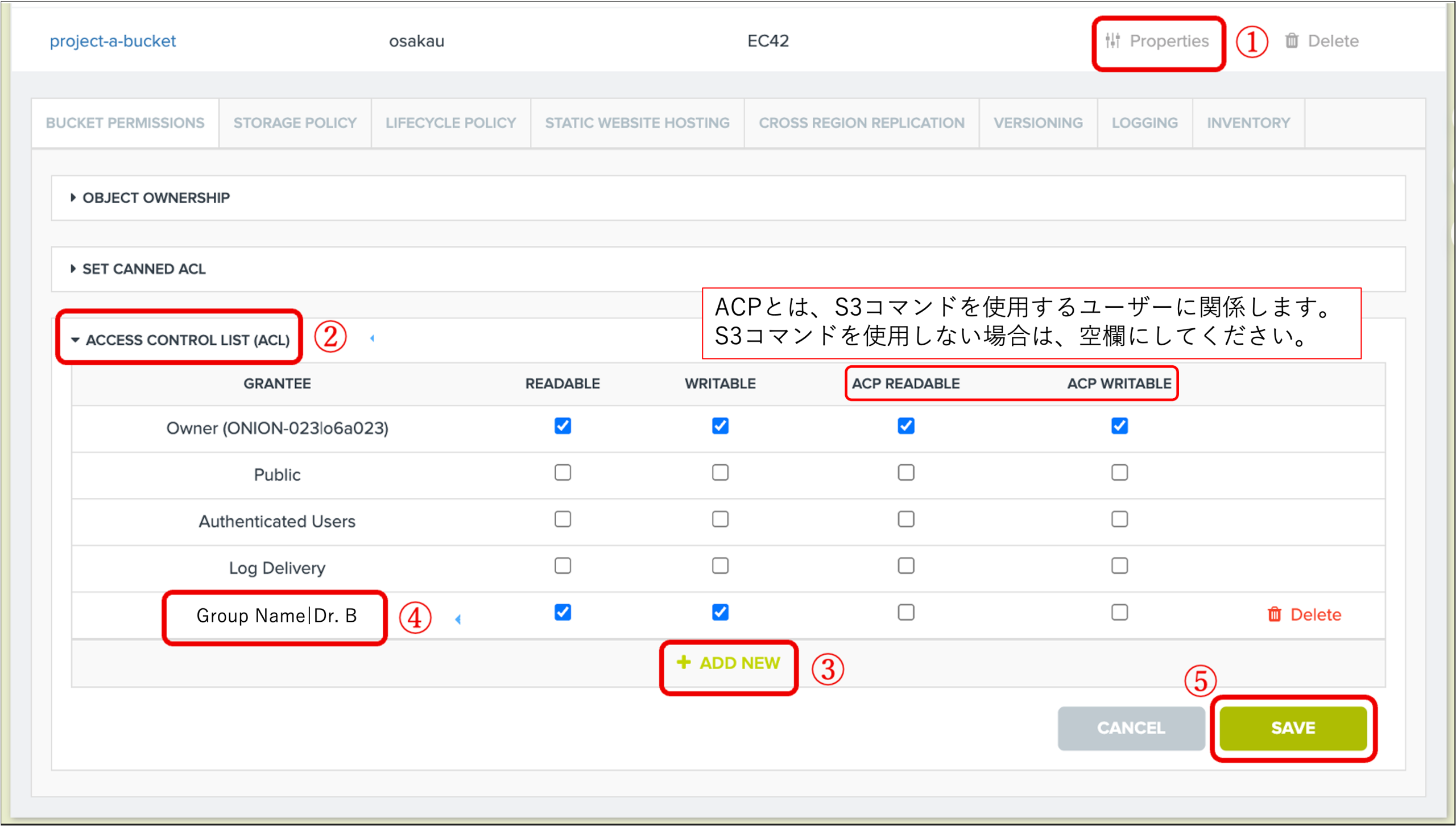
バケット全体を共有した場合(例1と例2)、共有相手(例1ではすべてのメンバー、例2ではDr. B)は、バケット内のすべてのフォルダやファイルの一覧を見ることはできますが、ダウンロードする権限はありません。
例3:project-a-bucket/data/dataset.csvを例に、 Dr. B にダウンロードを許可する場合:
特定のファイルを共有相手にダウンロードさせたい場合は、そのファイル単位で共有設定を行う必要があります。現在の機能では、バケットやフォルダ内の全てのファイルを一括で共有することができません。将来的に改善する予定です。
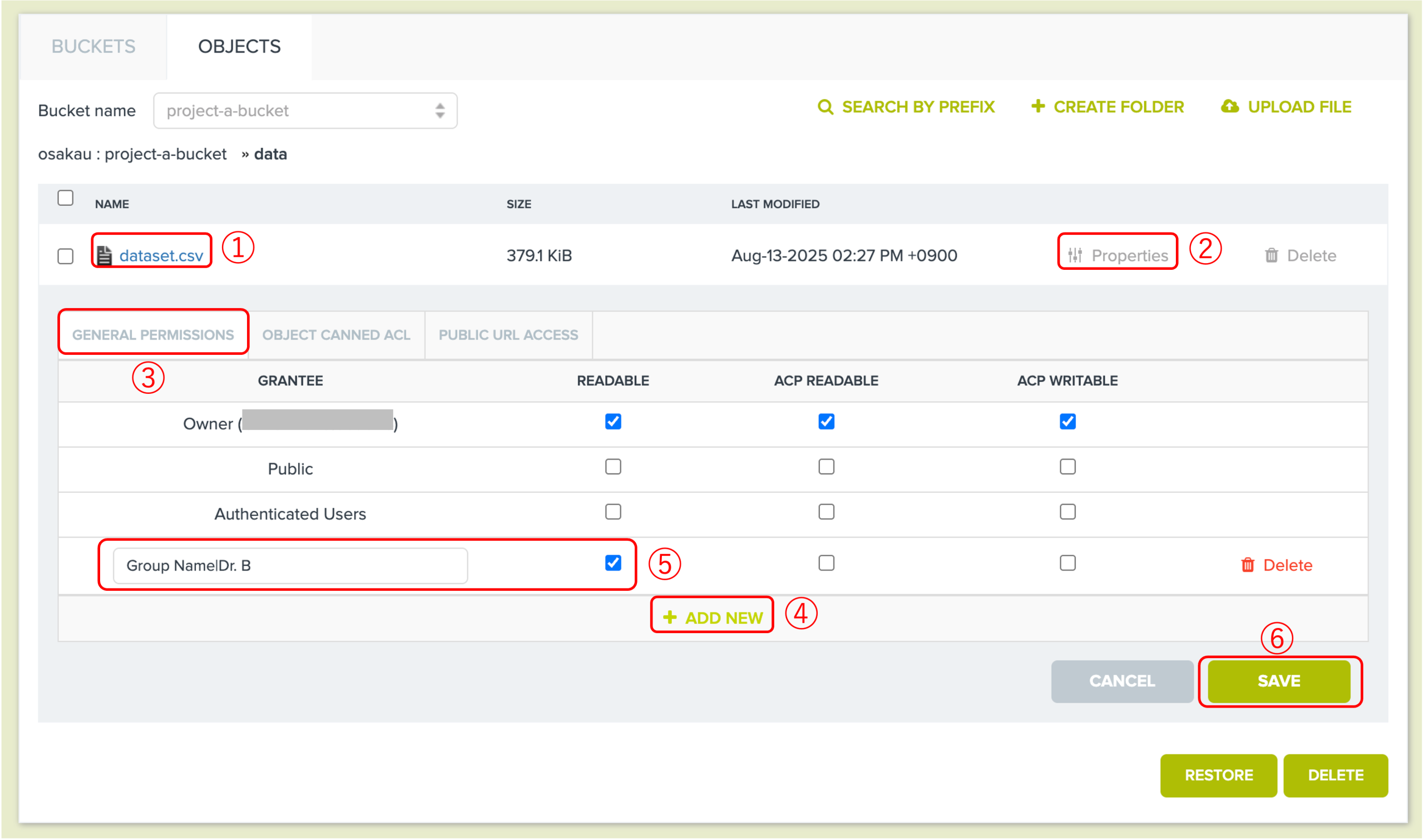
共有相手(Dr. B)はファイル『dataset.csv』をダウンロードできます。
2.2 データ所有者(Prof. A)から共有相手(Dr. B)へのデータパスの通知
データ所有者(Prof. A)は、共有方法に応じて以下の情報を共有相手(Dr. B)に通知する必要があります。
- バケット全体を共有する場合:バケット名
project-a-bucketを伝えてください。 - 特定のファイル(例:
dataset.csv)を共有する場合:project-a-bucket/data/dataset.csvファイルが保存されている場所を、バケット名から順番に伝えてください。
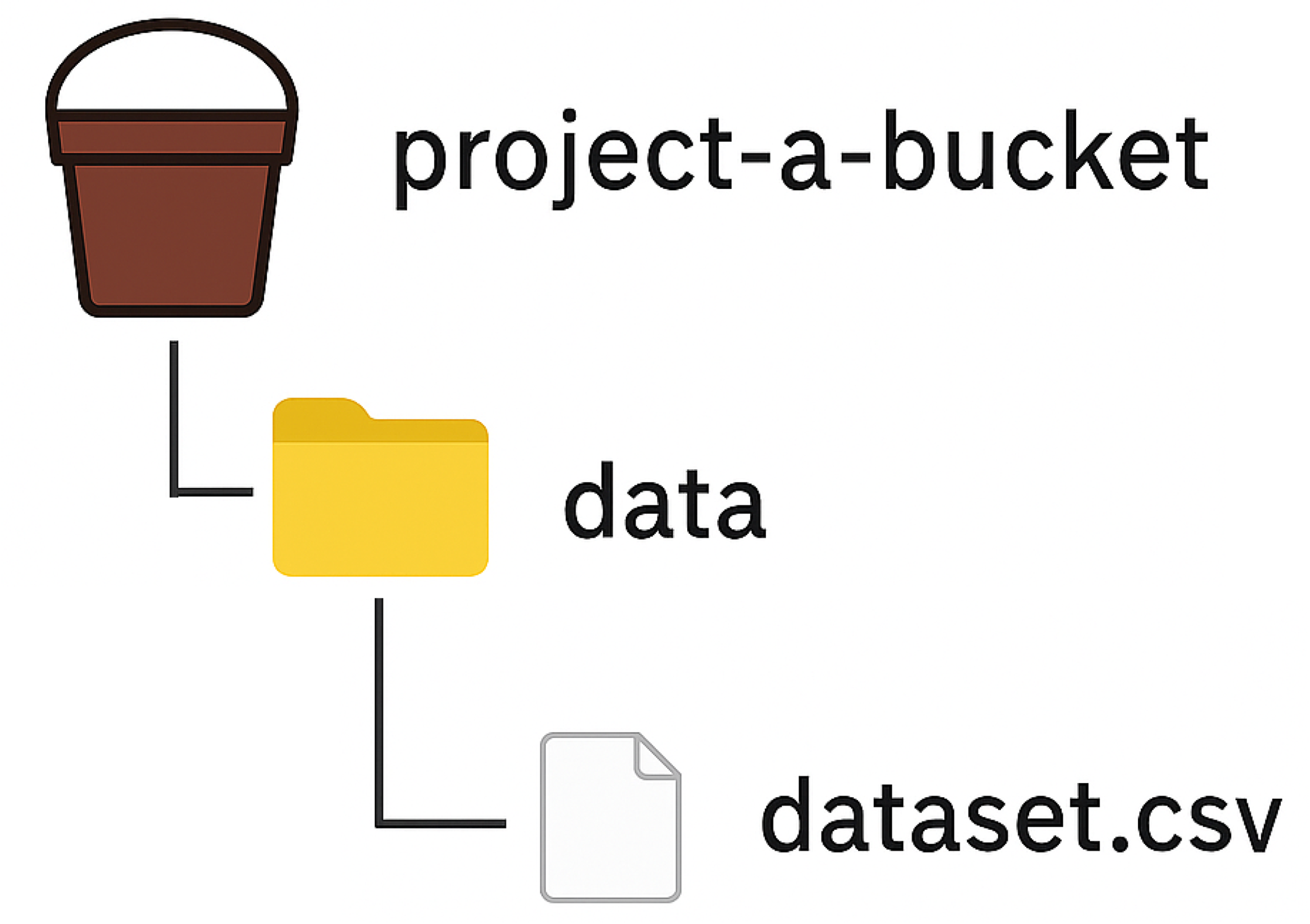
project-a-bucket/data/dataset.csv:→「project-a-bucket バケットの中の data フォルダにある dataset.csv ファイル」という意味です。
これにより、共有相手は正しくデータにアクセスし、操作できるようになります。
3. 共有相手による共有データの確認
データ所有者から通知された情報(2.2節参照)を元にデータにアクセスする方法を示します。現在は、AWS CLI(Command Line Interface)を使用してデータの確認を行う必要があります。
AWS CLIでは、Dr. BがAccess KeyとSecret Keyを用いて共有されたデータにアクセスすることができます。
なお、現在ブラウザ上で確認できるインターフェースを準備中です。
AWS CLIは、コマンドラインから AWS の各種サービス(S3、EC2 など)を操作できるツールです。
3.1 メンバー(Dr. B)による初期 AWS CLI 設定(Access Key、Secret Key、リージョン設定など)
Dr. B は、Prof. A が共有したバケットやファイルを確認・ダウンロードする際に、AWS CLI を使用して操作する必要があります。
3.1.1 AWS CLIのインストール
Mac OSの場合:Mac OSのターミナルアプリを使って、以下のコマンドを用いてAWS CLIをインストールしてください。
$ sudo ln -s /folder/installed/aws-cli/aws /usr/local/bin/aws
$ sudo ln -s /folder/installed/aws-cli/aws_completer /usr/local/bin/aws_completer
Windowsの場合:まず、Windows 用の AWS CLI MSI インストーラ(64ビット)をダウンロードし、実行してください。
インストールを確認するには、[スタート] メニューを開き、cmd を検索してコマンドプロンプトウィンドウを開いて、コマンドプロンプトで aws --version コマンドを使用します。
C:\> aws --version
aws-cli/2.27.41 Python/3.11.6 Windows/10 exe/AMD64 prompt/off
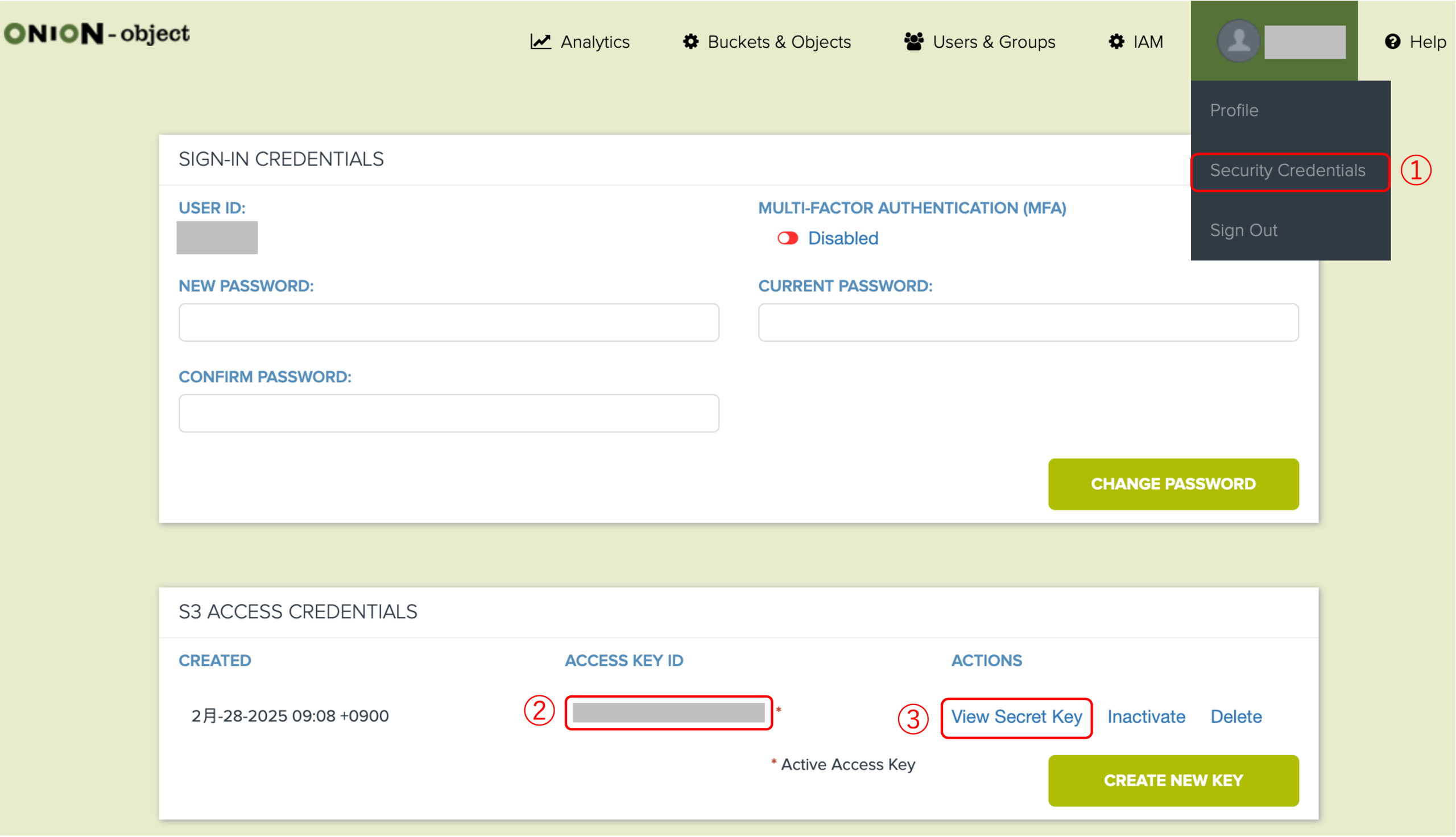
3.1.2 Dr. B の Access Key・Secret Access Key の取得:
以下の手順に従って、Dr. B は自身のアカウントから Access Key と Secret Access Key を確認・取得できます。
これらのキーは、S3 コマンドを使って Prof. A から共有されたデータを確認・ダウンロードする際の初期設定に必要です。
- ②:Access Key ID を確認します。
- ③:『View Secret Key』をクリックして、表示された Secret Access Key をコピーします。
3.1.3 AWS CLIの初期設定:
aws configure --profile=[profie name]
→次のようなメッセージが表示されます。
AWS Access Key ID [None]: (事前に取得したアクセスキーを入力してください)
AWS Secret Access Key [None]: (事前に取得したシークレットアクセスキーを入力してください)
Default region name [None]: (ONION-Objectの場合は"osakau"と入力してください。SQUIDの場合は設定不要です)
Default output format [None]:設定不要です。空欄のままEnterキーを押してください。
上の図の手順に従って Dr. B の AWS Access Key ID(②)および AWS Secret Access Key(③)を取得した後、Dr. B はターミナルで以下の AWS CLI コマンドを入力してください。
aws configure --profile=Dr. B
AWS Access Key ID [None]: ②
AWS Secret Access Key [None]: ③
Default region name [None]: osakau
Default output format [None]:
3.2 メンバー(Dr. B)から通知されたパスを用いた共有データの確認
Dr. B は、以下の S3 コマンドを Terminal(Mac OS の場合)で実行することで、共有バケットの内容(バケット内のフォルダ名やファイル名)を確認できます。
aws --profile=Dr. B \
--endpoint-url=https://s3-osakau.oniongw.onion.osaka-u.ac.jp \
s3 ls s3://project-a-bucket
※ バックスラッシュ(\)の後には空白を入れず、行末に必ず置くよう注意してください。\\ ※ 2026年1月11日~14日の ONION-Object メンテナンス後、AWS CLI の S3 endpoint URL が以下の通り変更されています。 (旧)https://s3-osakau.oniongw.hpc.cmc.osaka-u.ac.jp (新)https://s3-osakau.oniongw.onion.osaka-u.ac.jp 旧 endpoint を使用すると接続できませんので、必ず新しい URL を指定してください。 詳細は このページ をご参照ください。
実行すると、Terminal には次のように表示され、dataフォルダがあることが確認できます:
s3 ls s3://project-a-bucket
PRE data/
3.3 メンバー(Dr. B)による共有データのダウンロード
Dr. B は、Prof. A が共有したパス(project-a-bucket/data/dataset.csv)を用いて、以下の S3 コマンドを Mac OS の Terminal 上で実行することで、共有ファイルをDocumentsフォルダにダウンロードできます。
aws --profile=Dr. B \
--endpoint-url=https://s3-osakau.oniongw.onion.osaka-u.ac.jp \
s3 cp s3://project-a-bucket/data/dataset.csv ./Documents/
※ バックスラッシュ(\)の後には空白を入れず、行末に必ず置くよう注意してください。\\ ※ 2026年1月11日~14日の ONION-Object メンテナンス後、AWS CLI の S3 endpoint URL が以下の通り変更されています。 (旧)https://s3-osakau.oniongw.hpc.cmc.osaka-u.ac.jp (新)https://s3-osakau.oniongw.onion.osaka-u.ac.jp 旧 endpoint を使用すると接続できませんので、必ず新しい URL を指定してください。 詳細は このページ をご参照ください。
実行すると、Terminal には次のように表示され、Dr. B のDocumentsフォルダにコピーされます:
download: s3://project-a-bucket/data/dataset.csv to Documents/dataset.csv
4. 研究データの公開
4.1 研究データの一括ダウンロード
4.1.1 Dr. B が研究データを大阪大学附属図書館を通じて公開する場合、まずONION-Object 上の研究データをローカルにダウンロードする必要があります。
以下のコマンドを使うと、project-a-bucket 内のアクセス権のあるデータをまとめてローカルにダウンロードできます。
aws --profile=Dr.B \
--endpoint-url=https://s3-osakau.oniongw.onion.osaka-u.ac.jp \
s3 cp s3://project-a-bucket/ ./Documents/ --recursive
※ バックスラッシュ(\)の後には空白を入れず、行末に必ず置くよう注意してください。\\ ※ 2026年1月11日~14日の ONION-Object メンテナンス後、AWS CLI の S3 endpoint URL が以下の通り変更されています。 (旧)https://s3-osakau.oniongw.hpc.cmc.osaka-u.ac.jp (新)https://s3-osakau.oniongw.onion.osaka-u.ac.jp 旧 endpoint を使用すると接続できませんので、必ず新しい URL を指定してください。 詳細は このページ をご参照ください。
また、ONION-Object ダウンロード用のコマンド生成ツールも用意しています。
下記のフォームに必要事項を入力することで、自動的に実行可能なS3コマンドを作成できます。
ONION-Object ダウンロードコマンド生成ツール
ONION-Object ダウンロードコマンド生成ツールの使い方:
- 上記のフォームに、必要な情報(Profile Name、Bucket Name、圧縮するファイル名、ローカル保存先のパスなど)を入力します。
- 「コマンド生成」ボタンをクリックします。
- 表示された「ダウンロードコマンド」の【コピー】ボタンをクリックし、コピーしたコマンドをTerminal(MacOS)、またはPowerShell / コマンドプロンプト(Windows)で実行します。
4.1.2 ダウンロード後のファイル圧縮方法
- 上記の【ZIPパッケージ化コマンド】を Terminal(MacOS)または PowerShell/コマンドプロンプト(Windows)で実行すると、ファイルを自動的に圧縮できます。
- また、ダウンロード後に必要に応じて整理し、手動で ZIP ファイルにまとめることも可能です。
4.3 附属図書館への連絡
大阪大学附属図書館のリポジトリ登録支援システムで案内されている手順に従って、必要書類とZIPされた研究データを提出してください。
4.4 その他
ONION-Objectはバージョン管理のためのGitのような仕組みは備えていませんが、CLIコマンドを使ってローカルPCとONION上のデータを同期することができます。ここで「同期」とは、各研究者がローカルに保管しているデータがオリジナルであり、その内容をONIONにアップロードする/ONIONから必要に応じて取得する、という使い方を推奨します。
5. FAQ(よくある質問)
A1. Webページからのアップロードには、システム側の制約(Web UI / 逆プロキシ / ゲートウェイの設定)により、単一ファイルのサイズ上限があります。そのため、S3(ONION-object)に十分な空き容量(例:1TB)があっても、ブラウザ経由では数GB程度でアップロードに失敗することがあります。
Webページでアップロードできる最大サイズについて
- Web UI の上限は環境によって異なりますが、一般的に 数GB程度(例:2〜4GB前後) で制限されるケースがあります。
- 上限を超えるファイルは、Webページからではなく AWS CLI(コマンドライン)でアップロードしてください。
大容量ファイルの推奨アップロード方法(AWS CLI)
大きい動画(.mov)などは、AWS S3 cp を推奨します。
この方法は通常、ファイルを分割して送信する仕組み(multipart upload 相当)で、Webページ制限を回避しやすく、安定してアップロードできます。
なお、s3api put-object は方式上の制約があるため、大容量ファイルには適しておらず、正確なアップロード上限はシステム構成(ゲートウェイ設定やツール設定等)に依存します。そのため、大きなファイルは CLI を利用する方法が最も確実です。
- 単一ファイルをアップロード
以下は、Prof.A という AWS CLI プロファイルを使用して、ローカルの動画ファイル(video.mov)を lab-bucket にアップロードする例です。
aws --profile=Prof.A \
--endpoint-url=https://s3-osakau.oniongw.onion.osaka-u.ac.jp \
s3 cp "/Documents/video.mov" \
s3://lab-bucket/video.mov
- フォルダごとアップロード(複数ファイル)
以下は、Prof.A という AWS CLI プロファイルを使用して、ローカルのフォルダ名 VIDEOS 内のファイルをまとめて lab-bucket にアップロードする例です。
aws --profile=Prof.A \
--endpoint-url=https://s3-osakau.oniongw.onion.osaka-u.ac.jp \
s3 cp "/Documents/VIDEOS" \
s3://lab-bucket/VIDEOS \
--recursive